

(本文作家为 电厂,钛媒体经授权发布)
文 | 电厂,作家 | 董温淑,裁剪 | 高宇雷
在AI大模子的市集里,两年的时候足以重写一套共鸣。
2024岁首,壁仞科技联合独创东说念主徐凌杰离开GPU市集,回身创办了魔形智能(Magik Compute),要作念“AI Token Factory”。彼时这对大众照旧一个目生的说法。
但其时候迈进2026年,追随OpenClaw、Seedance等附近走向大众,“Token经济学”在极短时候内完成了行业表里的飞快破圈。
刚刚往日的3月,中国Token日均调用量冲突了140万亿。同月,黄仁勋在英伟达年度嘉会GTC 2026上预言“将来的数据中心会变成一个分娩Token 的工场”——与魔形的愿景异曲同工。
3月底,咱们在上海见到了徐凌杰,聊了聊魔形智能的主义愿景与业务模式;也试图借助他“局内东说念主”的视角,一窥Token工场、Token经济学,以及电力出海等养殖主张的背后真相。
从超节点与DeepSeek V2讲起,Token如何走入视线中央2024年1月18日,徐凌杰终末一次以壁仞科技总裁的身份发出里面信,文书我方行将辞职。信中谈及将来,他简短而奥密地写说念:
“AGI is calling,江湖再会。”
徐凌杰曾任职于英伟达、AMD、三星北好意思扣问院从事GPU研发、经管服务,并曾担任阿里巴巴阿里云智能业绩群总监。
在2019年壁仞科技诞生后,徐凌极品为联合独创东说念主之一,主要认真产物斟酌和市集拓展业务。
2024年,恰是壁仞多款拳头产物进入规模化量产、营收快速攀升的时候点;同庚9月,壁仞还启动了上市指令,行将开启国产GPGPU第一股的冲刺。
外界不免赞佩,徐凌杰为什么会在这个“得益时节”聘请回身。
3月底,在上海漕河泾开发区的一栋分享办公空间里,咱们见到了徐凌杰。从舆图上看,魔形智能与位于浦江的壁仞科技大楼相距不到半小时的车程,但两家公司的责任依然不同。
关于创业的时候聘请,他简短讲说念:“我和我的联合独创东说念主金琛看到的趋势是,在AI大模子和芯片之间,会有许多的服务需要作念。而2024年我40岁。东说念主生的黄金年事就这样几年,既然咱们认为Token的大潮立时要来了,那就要收拢我方元气心灵最好的这几年,勇于纵身。”
再具体一些,让他看清这个趋势的有两件事:
第一件是2024年的GTC大会上,英伟达发布了GB200 NVL72。这是一个集成了36个Grace CPU、72 个Blackwell GPU、悉数领有60万个零件、重达3000磅的“超节点(SuperPod)”机架系统。NVL72亦然英伟达“超节点”产物门路的代表之作。“超节点”顾名想义,是指通过高速互联技巧将多台服务器、数十乃至上百块GPU紧密集成的高性能狡计单元,号称“算力巨兽”。
第二件事,则是在2024年的5月,开源模子DeepSeek V2发布,凭借MoE(搀杂行家模子)、MLA(多头潜提防力)等技巧,一举将模子推理成本降至行业最低。数据的直不雅对比尤为惊东说念主,DeepSeek V2的每百万Token成本比拟同庚发布的GPT-5缩短了约96%。
一端是算力以“超节点”的格式被极致堆叠,另一端是模子通过结构立异约束压缩单元Token成本——供接纳后果,同期发生了跃迁。
Token迎来了可以被工业化分娩、精良化订价的可能性。这成了徐凌杰我方的aha moment:“其时咱们以为,V2这样的开源模子模子和超节点将是市集的绝配啊。”
作念软硬结合的AI Infra,已完成新一轮融资在写给壁仞共事的辞职信中,徐凌杰还写说念:“天然造芯之路告一段落,但还将效力在智能算力的大赛说念上”。
在2024年,这种表述不免让外界感到困惑。
“AI的三身分是算力、算法和数据”。很长一段时候内,这句话齐是大众谄谀一家AI公司市集定位的坐标系。
如同“CV四小龙”曾是算法的代名词,不管国外巨头英伟达照旧壁仞等国产GPU玩家,齐被等同于“算力”的代名词。
以数据中心、智算中心格式落地的算力租借生意,仅仅这个链条中偏重钞票、运维的一环。
要是芯片自己占据着算力价值链的尖端,一个新玩家在智能算力市集还能作念些什么?
徐凌杰将其表述为“软硬件协同的AI Infra”。在对魔形智能率先的媒体报说念中,有东说念主将其刻画为一家“作念算力优化”“服务器集群”的公司。在他看来,这并不贴切:
“算力优化仅仅咱们的才略,但不是咱们的mission statement。咱们是一家分娩高质地Token的公司。”
他进一步解释说念,单纯说算力优化,更接近传统软件行业的发展逻辑:相对芯片公司、数据中心、模子厂商而言,算力优化方是乙方,每付出一次优化服务、卖出一个License授权,取得一次性付费。
而魔形“不想成为上一代的软件公司”,而是径直租用服务器等硬件算力资源,进行模子部署、调优等系列服务后,径直向客户输出Token。
这种业务模式聚焦于“广义的AI Infra”,也即是将动力(电力)、芯片(算力)、Infra(推理和老师框架等技巧底座)、大模子封装在一起,径直对外输出Token。
“小龙虾或是任何一个Agent的用户,波音(bbin)体育官方网站不再需要注意折务器是何处来的,唯有在附近层去调用这个服务就可以了。”他解释说念。
4月发布的东吴证券研报提供了肖似的预判:算力租借厂营业务模式正从单纯的裸算力出租升级为模子服务或Token分红模式,营业模式有望从“卖算力”转向“卖Token”。
研报同期写说念,这种营业模式将面对三大壁垒:牢固的拿卡才略;强力的托福、上线和后续运营才略;资金盘活才略。
徐凌杰讲说念,在过往动力、芯片、Infra、大模子各自分立的行业结构里,东说念主才是分层的,想要变成软硬结合Infra的营业闭环就需要跨脉络的东说念主才,而“魔形的团队巧合有这样的东说念主”。
据了解,相较于徐凌杰过往深耕芯片硬件的从业履历,其结伴东说念主金琛曾任Graphcore中国工程副总裁和算法科学家,领有丰富的模子优化教会。
而在资金方面,「电厂」获悉,魔形智能刚刚于4月完成新一轮融资。
以下是与徐凌杰的对谈:
从“Token纳入薪酬体系”提及,当大模子运行产生经济效益Q:魔形是国内比较早说要作念AI Token Factory的公司。在3月斥逐的英伟达GTC 2026上,老黄也讲说念,将来的数据中心会变成一个分娩 Token 的工场。
你们语境中的“Token工场”的主张,跟数据中心、智算中心有什么远离?
A:咱们照旧借用黄仁勋建议的五层蛋糕表面来看。左证这个表面来分析市集模式的话,Token其实即是把底下四层的动力、芯片、infra、大模子给封装在一起了。你四肢一个小龙虾或是任何一个Agent的用户,不再需要注意折务器是何处来的,唯有在附近层去调用这个服务就可以了。
是以另一个角度,要是驳倒Token工场和数据中心有什么不一样的话。前者的主张是更靠近于糊口的。因为可能好多东说念主齐不知说念AI 芯片、服务器长什么神志,但Token四肢购买才能的一个单元,许多耗尽者依然有所感知。
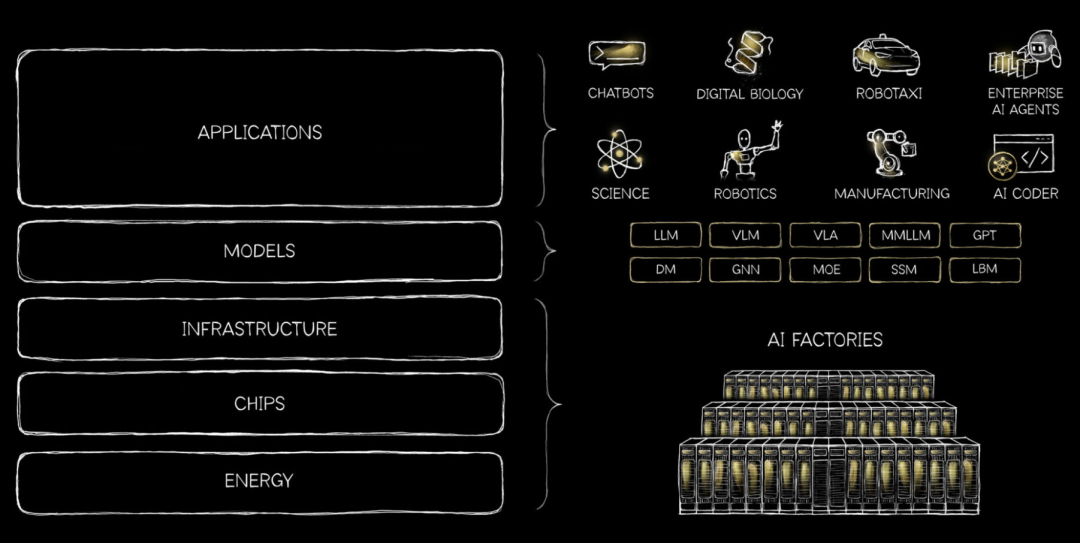
黄仁勋建议了AI的“五层蛋糕”表面,图/英伟达
Q:行业的叙事模式出现了变化?因为之前咱们讲的数据中心、服务器,是以英伟达这样的芯片想象玩家为中心的,Token工场的讲法更强调系统工程层面的变革、容纳了更多本事?
A:不仅是叙事上的变化,而是系数这个词行业在发展。
之前咱们更多激情到的行业进展,是某地落成算力中心、打造了千卡/万卡集群。这主要照旧因为那时产业正处在模子老师的阶段,也即是说模子还莫得达到被老匹夫无为使用的阶段。
这种近况得到变调的一个标识性事件——至少对中国来讲的话,是2025年DeepSeek V3的爆发,让大众俄顷发现“哎,模子能用了”。在那之后咱们又看到了许多附近的爆发,比如本年春节爆火的OpenClaw小龙虾。
今天来看,推理inference比拟老师training 来讲,将来的成长性会高好多。
是以说这不仅仅叙事模式的变调,能上下分的捕鱼app官方版下载更是经济效益的再分拨经过。
可以举个例子来看,目下好多公司依然在给工程师进行Token的配额,比较常见的是一个月一两千元价值的Token,是以说模子依然在分娩中着实地被用起来了。
Q:在这个经过里,魔形智能的位置是?
A:大众关于更快、才能更高、更大规模分娩的Token有需求的。而这需要更大的集群。
今天在中国,包括DeepSeek在内,存在大批的优质开源模子。当模子长入面向系数东说念主开源时,在将来一段时候内,大众要激情的即是若何把硬件组织得更好、让模子跑得更好,这即是Infra要作念的事情。
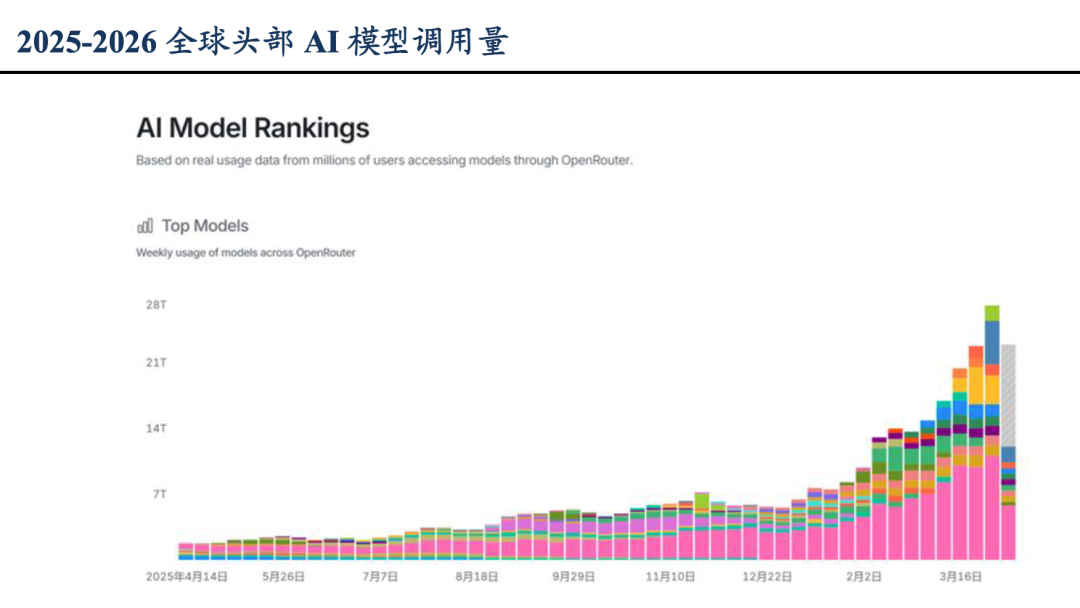
2026年元旦之后,全球头部模子Token调用量大幅上涨,数据/OpenRouter,图/东吴证券
Q:您之前在交大的一个采访里提到,魔形智能对标的是Nebius,但走得更深、全栈自研。该若何谄谀这种底层自研?
(Nebius:好意思股上市的垂直整合云服务提供商,获英伟达投资,搁置2025年Q2估值为约160亿好意思元)
A:Nebius和其他好多Infra企业不同的是,它有一部分服务器是自研的。它们把采购来的服务器作念了改配、进行长入化的建立,让服务更牢固。
这样带来的平正是什么呢?按照之前Meta老师Llama 3的数据,服务器可能每隔一段时候就会面对故障中断,为此老师团队连接地进行Checkpoint 保存老师数据、恭候服务器还原、再从头reload数据。
(注:在Llama 3.1老师的54天里,Meta的1.6万块H100集群总共遭遇了419次随机中断,至极于平均每3小时发生一次。)
但假定用Nebius的服务器来老师,即便它的单价更高,可是因为牢固性更好、故障中断率更低,模子也能更快老师出来。
今天咱们讲对标Nebius,更多地是想要强调软硬件齐需要作念,而不仅仅像上一代公司一样只聚焦软件、只聚焦芯片资源。但今天从全天下范围来看,绝大部分Infra企业还齐是以软件的方式去作念。
咱们有一个对标的想维惯式。但其实好多聘请并莫得前路可循,再往后走,需要咱们去进行第一性旨趣的判断,而不是随从谁。
“用若干电,产生若干Token”成为新的坐标系Q:之前推测一个数据中心的性能,咱们会讲它是万卡照旧千卡、单卡的flops是若干;目下迎面对一个Token工场时,咱们应该用什么样的目的去推测它?
A:用若干电,产生了若干Token。
Q:这可以等同于黄仁勋说的“谁的每瓦Token隐晦量最高,谁的分娩成本就最低”?
A:今天当咱们看到一个数据中心,第一个问题经常会去问“你是若干兆瓦的?”。而这个电力决定了你的装机量上限,进而再去谈每天分娩了若干Token。
黄仁勋这句话可以用来评价后果。毕竟不同品牌、卡与卡之间的性能并不均等——英伟达卡和AMD卡即便雷同标称1万PFLOPS,亦然不行完全等同的,分娩后果也并不同。可是电力是能够直不雅去作念比较的、最好量化的。
天然,模子才略不同,产生的Token才能也会相称不一致。大体来讲,参数目越大的模子的Token越聪惠。雷同的数据中心用来分娩7B、13B模子的Token,和用来分娩Deepseek 671B模子的Token,分娩后果也会相称不同。
Q:按照目下比较优质的智算工场,Token的单元电力隐晦量应该在若干?
黄仁勋说“Vera Rubin在合并座1GW数据中心里,让将Token的生成速度从2200万进步到了7亿”。这是行业的最好成绩吗?
A:具体的数字啊咱们可以先放一放。单论产生若干Token的全齐数字,这是和一些逼迫条款相关系的,比如模子参数目、比如所谓的离线模式和在线模式——在线模式即是延时要很低,问题过来要在一两秒内回话;离线模式可能30分钟之后才有收尾。
大厂在发布新的解决有斟酌的时候,也会小字标注进展最好性能的各式前提条款。
总之我以为咱们可以先忽略全齐数字,来看和Token分娩后果相关的变量条款。可以激情的点包括芯片自己的性能,比如从Grace Blackwell到Vera Rubin是一个升级;第二个是超节点的升级,从NVL72变成了NVL144;第三个是Format(格式)的不同,激情数据中心是用8bits照旧用4bits去作念狡计。
Q:在Token工场的范围里,英伟达它照旧一个天花板的存在吗?
A:天然,我在英伟达服务过。系数东说念主到了那里之后,学会的第一个词叫 speed of light(光速)。
speed of light代表着极限,查考你的服务是否作念得实足好,即是用speed of light四肢一个目的,公司的文化是鼓舞每个东说念主往100% speed of light去走。
毫无疑问,目下英伟达照旧技巧极限的追求者和界说者。
刻下市集比拼的一个是全齐性能,第二个即是单元的性价比。我以为对今天的中国公司来讲,更紧迫的是追求单元的性价比。
电力出海是伪命题,但Token市集康庄大道Q:魔形智能的公众号里有几篇著述,拆解过开垦Token工场的身分,分袂是高压直流输电、液冷、高速互联、超节点架构下的推理优化和软硬协同。要变成这种高度系统化的解决有斟酌,需要魔形作念哪些准备和奋勉?
A:永久来看是要往超节点的路去走,它是一个系统化的工程,刻下咱们细则还在路上,但在路上也可以“一起下蛋”。比如目下可以去奋勉优化运营成本,在能够获取到的硬件的基础上进行优化。
在现阶段,在硬件方面去下功夫口角常有必要的。今天来看Token的成本结构,里面有约80%是和服务器的采购成本相关的。是以一定要措置硬件、掌抓供应链的要津本事,才有可能达到梦想的成本。
今天在中国市集的每秒钟产生的Token(TPS,Tokens Per Second)约略是在30到60个,在好意思国这个数字可能是达到100、200。这齐是因为咱们还受限于算力的供给。
Q:魔形智能会探究自研芯片吗?
A:这个相对还比较远处,不在咱们的目下的roadmap里面。
魔形一定是面向提供Token动身,服务器、集群会是这个模式的副产物。
Q:刻下国内还有硅基智能、清程极智这些公司,也在AI Infra的赛说念里,那魔形智能的特有性体目下何处?
A:今天的市集还莫得到彼此竞争的阶段。
就像当初的芯片市集,假如一家芯片公司在2020年融完资后,就以为市集的钱齐被吸完毕、窗口期关闭了,那就错了;事实阐述,2021年又诞生了好多芯片公司,好多也成长得可以。
AI Infra的市集盘子会比芯片更大,但今天系数这个词赛说念的成本参加还远未达到芯片赛说念的进度。大众在这个赛说念里,面对的齐是百倍千倍的成长契机。
三年之后,这个赛说念里面细则能跑出千亿级别东说念主民币以上的公司,况兼可能不啻一家。要是咱们今天只从竞争的角度来看市集,模式就小了。
Q:查贵寓可以看到,目下AI Infra比较常见的营业模式有两种,一种是和 IDC 运营商、GPU云服务商、国产芯片厂商共同对外提供Token服务,另一种是为已有自建 GPU 集群算力消纳、优化服务。还有别的可能吗
A:这两种齐是潜在的标的,咱们目下作念的更接近于是第一种,即是和算力中心互助。咱们是甲方,他们是乙方,用他们的机器来分娩Token。
这也波及到一个聘请问题。既然咱们认为我方的产物是Token自己,分娩高质地的Token、把这件事作念到营业闭环即是咱们最遍及的任务。
第二种的算力消纳模式,可能会是将来咱们扩大我方资源的一种方式。
Q:最近“token出海”“电力出海”的主张很火,强调的是国产动力上风的系统变现,这在营业模式上可行吗?
A:今天讲token出海的东说念主,不知说念是不是有利忽略了一个点。他只算了电力成本,但电力成本在Token成本里占不到10%,算力成本才是最中枢的。但中国的算力目下有上风吗?没上风。咱们我方算力齐不够用。
将来跟着咱们国度的芯片水平提高能上下分的捕鱼,这种愿景可能会达成,但昭彰不是当下的命题。
IM体育官方网站首页 备案号:
备案号: